LLM Observability for Laravel - trace every AI call with Langfuse

How much did your LLM calls cost yesterday? Which prompts are slow? Are your RAG answers actually good?
If you're building AI features with Laravel, you probably can't answer any of these.
I couldn't either. So I built a package to fix it.
Laravel is ready for AI. Observability wasn't.
The official Laravel AI SDK launched in February 2026. It's built on top of Prism, which has become the go-to package for LLM calls in Laravel. Neuron AI is gaining traction for agent workflows. With Laravel 13, AI is a first-class concern in the framework.
Building agents, RAG pipelines, and LLM features with Laravel is no longer experimental. But once those features run in production, you're flying blind.
Which documents are being retrieved? How long does generation take? What's the cost per query? Is the output actually correct? Python and JavaScript developers have had mature tooling for these questions for years. Langfuse, LangSmith, Arize Phoenix - the list is long.
Laravel had nothing.
What is Langfuse?
Langfuse is an open-source LLM observability platform. Think of it as "Sentry for your LLM calls" - but purpose-built for AI applications.
It gives you:
- Tracing - every LLM call, retrieval step, tool invocation, and agent action in a nested timeline
- Cost tracking - token usage and costs per model, per user, per trace
- Prompt management - version, deploy, and A/B test prompts from a central UI
- Evaluation - attach scores to traces, run LLM-as-judge evaluators, collect user feedback
It's self-hostable or available as a managed cloud service. Open source, 24K+ GitHub stars, used by thousands of companies, and recently acquired by ClickHouse.
The platform is excellent. But the SDKs are Python and JavaScript only. No PHP.
laravel-langfuse
So I built laravel-langfuse - a Laravel package that connects your app to Langfuse with a clean, idiomatic API.
Install it:
composer require axyr/laravel-langfuse
Add your credentials:
LANGFUSE_PUBLIC_KEY=pk-lf-...
LANGFUSE_SECRET_KEY=sk-lf-...
Trace an LLM call:
use Axyr\Langfuse\LangfuseFacade as Langfuse;
use Axyr\Langfuse\Dto\TraceBody;
use Axyr\Langfuse\Dto\GenerationBody;
use Axyr\Langfuse\Dto\Usage;
$trace = Langfuse::trace(new TraceBody(name: 'chat-request'));
$generation = $trace->generation(new GenerationBody(
name: 'chat-completion',
model: 'gpt-4',
input: [['role' => 'user', 'content' => 'What is RAG?']],
));
// After the LLM responds:
$generation->end(
output: 'RAG stands for Retrieval-Augmented Generation...',
usage: new Usage(input: 24, output: 150, total: 174),
);
That's the manual API. But the real power is in what comes next.
Zero-code auto-instrumentation
This is the feature I'm most excited about.
If you use Prism for LLM calls, add one line to your .env:
LANGFUSE_PRISM_ENABLED=true
Every Prism::text(), Prism::structured(), and Prism::stream() call now automatically creates a trace and generation in Langfuse. Model name, parameters, token usage, latency, errors - all captured without touching your application code.
Same for the Laravel AI SDK:
LANGFUSE_LARAVEL_AI_ENABLED=true
Every agent prompt, every tool invocation, every streamed response - traced automatically. Agent calls create traces with generations, tool calls create spans with arguments and results.
And for Neuron AI:
LANGFUSE_NEURON_AI_ENABLED=true
The package wraps each framework's internal event system or provider layer. Your code doesn't change. You just get visibility.
What it looks like in practice
Here's a real trace from a RAG pipeline - a retrieval span with an embedding generation and vector search, followed by a completion generation. All sent from Laravel, all visible in the Langfuse dashboard:
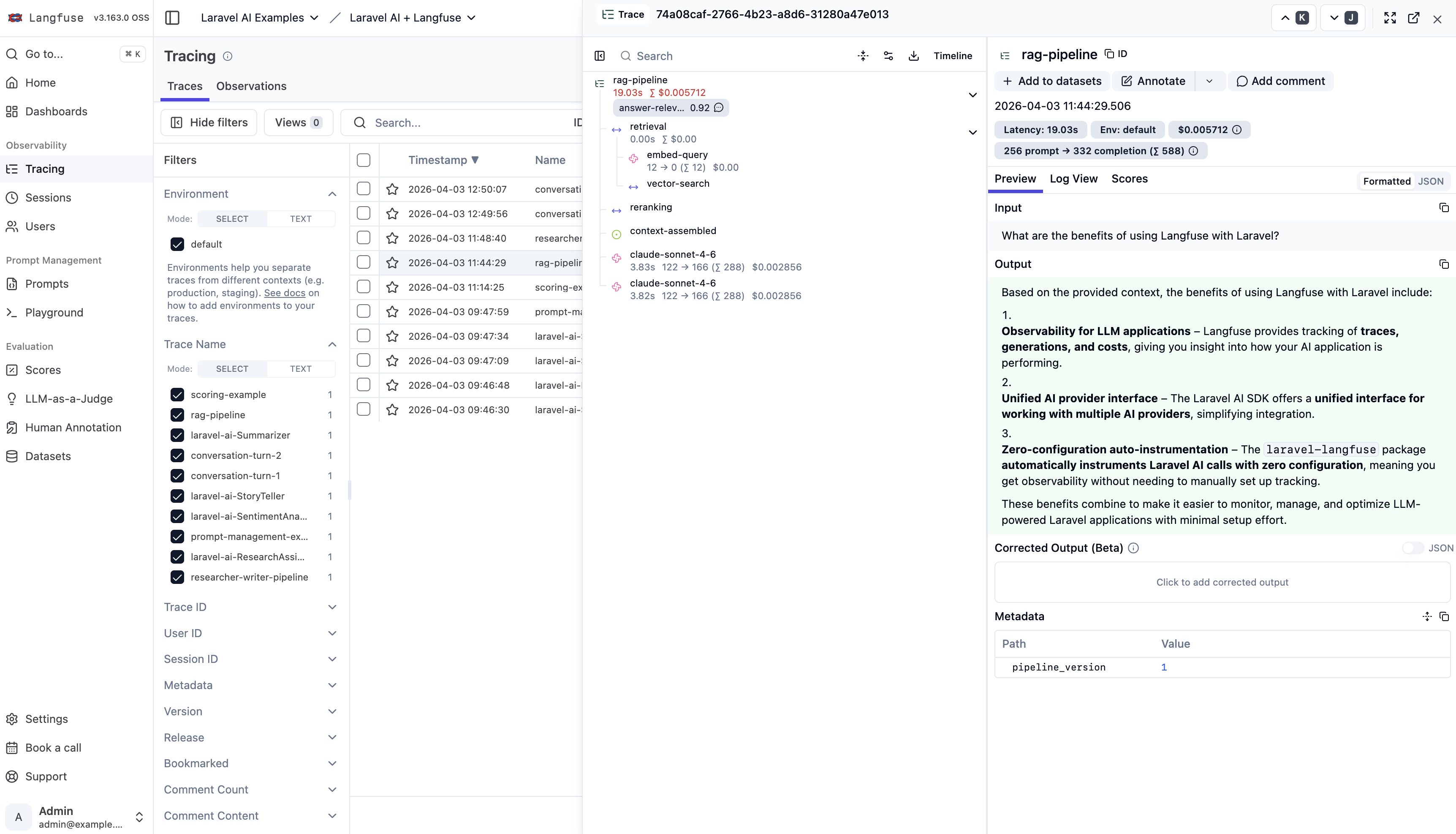
You can see the full nested structure, token counts per generation, total cost, latency breakdown, the actual input/output, and even an evaluation score (answer-relevance: 0.92).
This is what was missing.
Per-request tracing with middleware
Add the middleware to your routes and every HTTP request gets its own trace. All LLM calls within that request automatically nest under it:
use Axyr\Langfuse\Http\Middleware\LangfuseMiddleware;
Route::middleware(LangfuseMiddleware::class)->group(function () {
Route::post('/chat', ChatController::class);
});
The trace picks up the route name, authenticated user ID, and request metadata. Three Prism calls in one request? One trace, three nested generations. No manual wiring.
Prompt management
Fetch prompts from Langfuse, compile them with variables, and link them to your traces:
$prompt = Langfuse::prompt('movie-critic');
$compiled = $prompt->compile(['movie' => 'Dune 2']);
$generation = $trace->generation(new GenerationBody(
name: 'review',
model: 'gpt-4',
promptName: $prompt->getName(),
promptVersion: $prompt->getVersion(),
));
Prompts are cached in-memory with stale-while-revalidate. If the API is down, the stale cache is returned. If nothing is cached, you can provide a fallback:
$prompt = Langfuse::prompt('movie-critic', fallback: 'Review {{movie}} briefly.');
Testing
The package ships with a fake that records events without making HTTP calls:
$fake = Langfuse::fake();
// Run your application code...
$trace = Langfuse::trace(new TraceBody(name: 'test'));
$trace->generation(new GenerationBody(name: 'chat'));
// Assert what happened
$fake->assertTraceCreated('test')
->assertGenerationCreated('chat')
->assertEventCount(2);
Follows the same pattern as Http::fake() and Queue::fake(). If you know Laravel, you already know how this works.
Production-ready
A few things that matter when this runs for real:
- Octane compatible - scoped bindings reset per request, no state leakage
- Queued batching - set
LANGFUSE_QUEUE=langfuseand events dispatch as jobs instead of sync HTTP calls - Graceful degradation - API failures are caught and logged, never thrown
- Auto-flush on shutdown - queued events flush when the application terminates
- Langfuse v2 and v3 - works with both, cloud and self-hosted
Try it
The package is on Packagist:
composer require axyr/laravel-langfuse
I created example projects for each integration so you can see everything working end to end:
- Laravel AI + Langfuse - agents, tools, streaming, scoring
- Prism + Langfuse - text, structured output, streaming
- Neuron AI + Langfuse - agent workflows
Full docs and source: github.com/axyr/laravel-langfuse
Feedback, issues, and stars welcome. This is the observability layer that Laravel's AI ecosystem was missing. Let's fix that.